Best LLM for Meeting Summary: Why Locked-In Tools Lose, and What to Pick Instead
If you've ever read an AI-generated meeting summary and thought "this missed the whole point" or "this invented action items nobody actually committed to," you've run into the LLM-fit problem. Different models have measurably different strengths in summarising meetings — long-context handling, multilingual coverage, prose quality, instruction-following, cost per summary. The model that's strongest on one of those dimensions is rarely strongest on all of them.
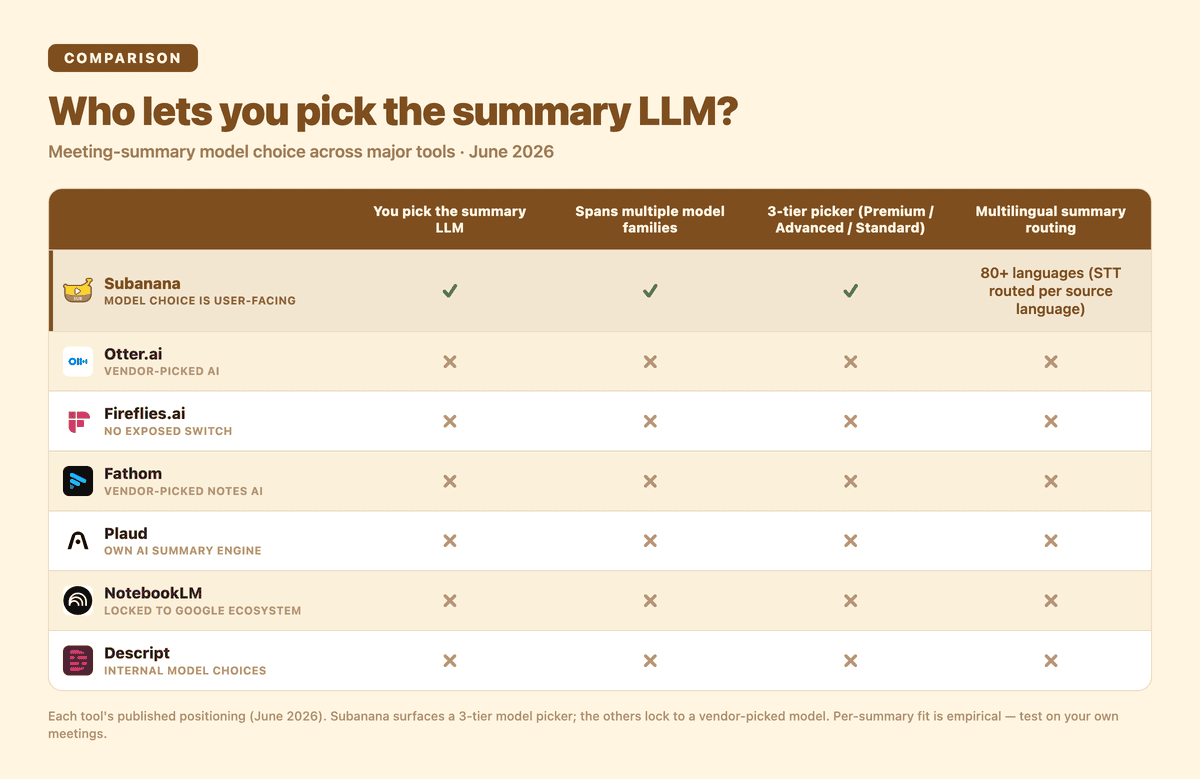
Who lets you pick the summary LLM, at a glance — Subanana surfaces a 3-tier model picker; the other tools lock to a single vendor-picked model.
Most meeting transcription tools — Otter, Fireflies, Fathom, Descript, Plaud, NotebookLM — pick one model (or one within a tier they don't expose) and lock you to it. When the vendor's pick doesn't fit your meeting type, your summary suffers and you have no way to fix it short of switching tools.
This post is about how to think about the choice, with honest disclosure: I run Subanana. Subanana lets users pick the LLM that writes their summary — the only feature in our product where the model selection is a user-facing decision. The thesis applies whether or not you use Subanana: the point is to understand the dimensions, then evaluate any tool's approach against them.

TL;DR
- No single LLM is "best for meeting summaries." The right model depends on what your meeting is and what kind of output you need.
- Long meetings (90+ minutes) reward long-context models. Context-window capacity varies materially across families.
- High-velocity meetings reward speed-optimised mid-tier models. Action-item extraction and clean structured output matter more than reasoning depth.
- Multilingual meetings reward multi-model approaches more than any single "multilingual" model. The right summary-LLM for non-English or mixed-language content is rarely the same as for English-only.
- High-stakes communications reward premium-tier flagships with prose quality. Marginal cost is small; output difference is meaningful.
- Routine internal meetings reward budget-tier models. Throwing a flagship at a 15-minute team sync wastes its reasoning depth.
The practical answer for most users is: default to a mid-tier model, switch to premium for the meetings that actually matter, and don't agonise over specific version numbers. Tier structure is stable; specific frontier models inside each tier change every few months.
The dimensions that actually vary
Five axes where LLMs differ meaningfully for meeting summary work:
- Context window. How much transcript can the model hold in one shot? A 30-minute meeting is comfortable for most models; a 3-hour board meeting separates the long-context flagships from everything else.
- Instruction-following. When you ask for "decisions, action items, follow-ups in that order," does the model deliver that structure cleanly, or does it freelance? Strong instruction-following models produce summaries you can ingest into a downstream workflow without reshaping.
- Hallucination resistance. Does the model fabricate action items that weren't actually agreed? Premium-tier reasoning models tend to be more conservative; budget-tier models can paraphrase loosely under pressure.
- Multilingual handling. Models trained predominantly on English produce visibly worse summaries of non-English and mixed-language content. The gap is bigger than vendors usually admit.
- Cost per summary + latency. Flagship-tier models can cost 5-10× a mid-tier model for output you may not notice the difference on. Latency varies similarly.
Notice what's missing from this list: an aggregate "intelligence" score. Public LLM benchmarks (MMLU, HumanEval, etc.) rank models on aggregate tasks that are mostly not meeting-summary tasks. A model that wins on math reasoning doesn't necessarily win on extracting decisions from a strategic discussion. Treat aggregate benchmarks as noise for this specific use case.
Why most meeting tools don't let you pick
Look at how the major meeting tools handle LLM choice:
- Otter.ai — vendor-picked AI for summary; no user choice of underlying LLM
- Fireflies.ai — vendor-picked AI for summary; no exposed switch
- Fathom — vendor-picked AI for notes; no user switching
- Plaud — hardware device sends recordings to its own AI summary engine; no model picker
- NotebookLM (Google) — locked to Google's own model ecosystem
- Descript — vendor-picked internal model choices; no user picker
The lock-in pattern is universal. Each vendor designed their product when "the LLM" was effectively one mainstream choice, and re-architecting to a multi-model system is non-trivial — different APIs, different prompt engineering per model, different cost-tracking infrastructure. Most vendors decided model choice wasn't worth user-facing differentiation. Subanana made the opposite bet: model choice is a user-facing decision worth surfacing in the picker.
How Subanana's approach works
Subanana's meeting-summary feature presents a 3-tier picker: Premium, Advanced, Standard. Inside each tier sit multiple frontier models from different families. You pick the tier (or the specific model, if you have a preference); your summary gets written by that model.
The tier structure is stable; the specific models inside each tier rotate continuously. New frontier models are evaluated against four criteria — intelligence, throughput, pricing, context-window — and added when they outperform an incumbent at their tier. Underperformers get rotated out. From the user's view, the tier picker quietly improves over time without their having to track individual model launches.
Three things to call out:
- No vendor lock. No commitment to one provider. The roster spans multiple major model families.
- No "Preview" suffix in the UI. Preview-tagged models may be used behind the scenes, but the picker shows base names only — reducing the cognitive load of distinguishing preview vs GA at the routing layer.
- A model's absence isn't a rejection. Anthropic's Claude, for example, isn't currently in Subanana's menu. That's an outcome of rolling evaluation against the four criteria — pricing, access constraints, throughput against alternatives — not a permanent exclusion. As those factors evolve, the menu evolves.
For the current specific version names inside each tier, refer to the model picker inside the Subanana app — that menu is the live source of truth, not this blog post.
Practical picking guide
The framework most users need is short:
Pick PREMIUM tier when:
- The meeting really matters (board meetings, strategic planning, customer escalations, legal proceedings)
- The meeting is long (90+ minutes — context-window capacity becomes a differentiator)
- The output goes to executives or clients without heavy human editing — prose quality is load-bearing
Pick ADVANCED tier (the default for most meetings) when:
- Routine internal meetings, sales calls, customer-success check-ins, project syncs
- Speed + clean structured output matters more than maximum reasoning depth
- The marginal quality difference vs Premium isn't worth the ~3-5× cost ratio for your use case
Pick STANDARD tier when:
- High-volume routine summaries (multiple meetings per day per user)
- 15-minute check-ins where any structured summary is more valuable than no summary
- You're cost-sensitive and Premium's reasoning depth would be wasted on the content
For multilingual or mixed-language meetings: the underlying transcription routing handles the speech-to-text language step (Subanana benchmarks STT models per source language and routes to the best evaluated one across 80+ supported languages). For the summary step, the picker still applies — try a Premium or Advanced tier and compare on your actual content. There's no single "multilingual specialist LLM" that wins across all non-English content; the right pick is empirical, not theoretical.
When to generate twice
For high-stakes summaries (board minutes, legal readouts, customer escalation reports), running the same transcript through two different models can be worth the doubled cost. You're not running a benchmark — you're hedging against one model's blind spot for your specific content. Pick the better output, or merge the strongest parts.
This is a manual workflow today: trigger the summary, switch the LLM in the picker, trigger again. Worth it for meetings where the output will be read closely; overkill for routine content.
Frequently asked questions
Isn't picking an LLM too technical for most users?
Subanana's UX presents the 3-tier picker (Premium / Advanced / Standard), so users who don't want to think about specific models can pick a tier and let Subanana route to one of the current best-evaluated models at that tier. Users who care about a specific model can pick by name. Both audiences are served.
Will the "best" LLM change in 6 months?
Almost certainly yes. The roster evolves continuously. The tier structure is what's stable — "frontier flagship vs mid-tier vs budget" remains a useful distinction even as the specific models inside each tier rotate. Treat any specific model recommendation as a snapshot, not a commitment.
Why isn't Claude in Subanana's menu?
Subanana's roster is curated against four criteria: intelligence, throughput, pricing, context-window. Claude's presence or absence on any given date is an outcome of that rolling evaluation — not a permanent rejection. As pricing, performance, and access factors evolve, the menu evolves with them.
Why doesn't every meeting tool let me pick?
Most tools were built when there was effectively one mainstream model choice — the product surface was designed around a single model. Re-architecting to multi-model means different APIs, prompt-engineering per model, and cost-tracking per provider. Most vendors decided the engineering cost wasn't worth user-facing differentiation. Subanana made the opposite bet.
Are there meetings where Standard tier really is better than Premium?
Yes — many. Routine status updates, casual brainstorms, quick check-ins. Throwing flagship-tier reasoning at a 15-minute team sync wastes the reasoning depth and pays for capacity you don't use. For routine content, Standard tier produces summaries indistinguishable in usefulness at a fraction of the cost.
Can I migrate my summary history to a different tool if I switch?
Yes. Summaries export as DOCX, PDF, TXT, or Markdown — standard formats portable to any other tool. What doesn't transfer cleanly is the model-per-summary metadata (which LLM wrote which summary, when) — that's specific to Subanana. Most meeting tools export summaries in similar standard formats, so the migration cost on summary export is low.
Does Subanana publish per-model accuracy benchmarks?
No public per-model benchmarks. Per-model performance varies materially by meeting type, audio quality, language mix, and content domain — a single number would be misleading. The recommendation across this post is: test on your own actual meetings, where the model's fit to YOUR content is what determines the value.
Related guides
- Best AI Meeting Transcription Tools 2026 (EN hub)
- Subanana vs Otter (2026)
- Subanana vs Fireflies (2026)
- Subanana vs Fathom (2026)
- 2026 Hong Kong AI Meeting Tools (zh-HK)
Methodology note
This post is about how to think about model choice, not a benchmark report. Specific per-model performance numbers aren't published here — model performance varies by version, by meeting type, by audio conditions, and updates faster than any blog snapshot can keep up with. The right way to settle "which LLM works best for MY meetings" is to test on your actual content. Any Subanana free-tier account supports that test directly.