Translation vs Interpretation: What's the Difference (and Where Live Captions Fit)
The difference in one line: translation converts written text from one language to another, while interpretation converts the spoken word in real time as someone is talking. A translator works on a document and has time to research, revise, and get every word right; an interpreter works on live speech and has to render it on the spot, with no second take. Same goal — moving meaning across a language barrier — but two different jobs, two different skill sets, and increasingly a third option (AI live captioning) that sits between them.
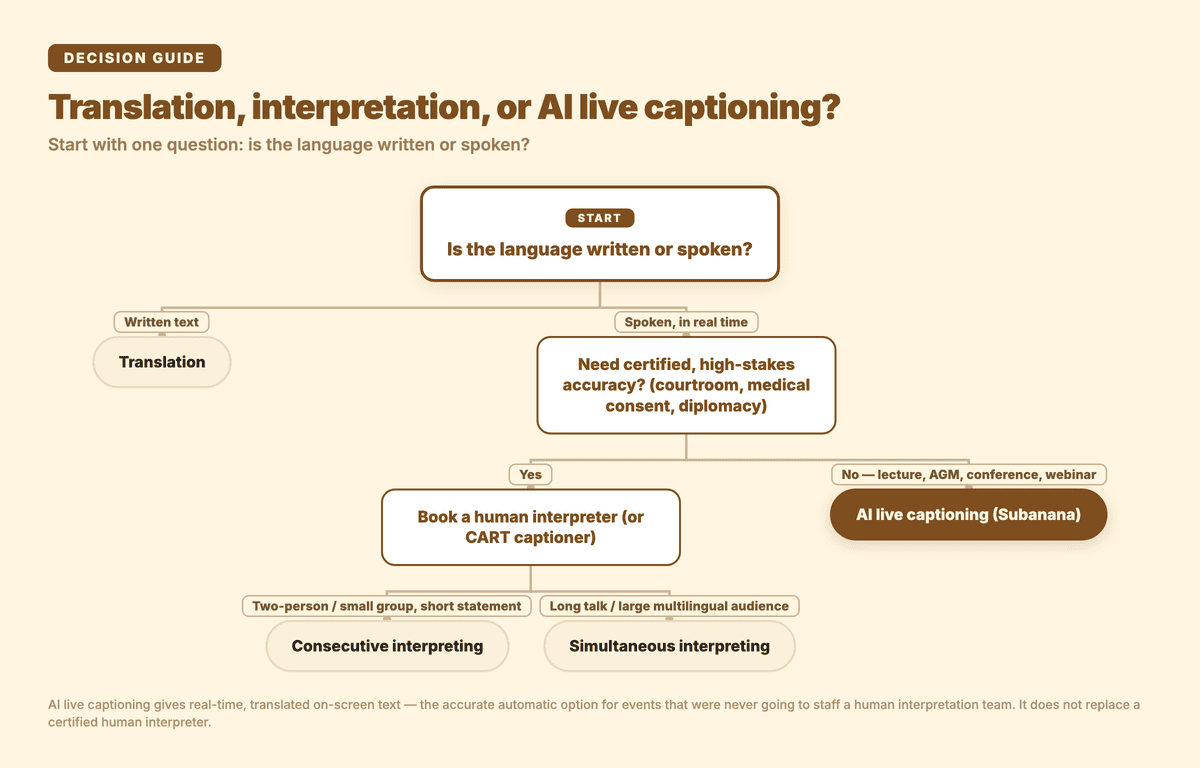
Which one your event needs, at a glance: written text means translation; live speech means a human interpreter or AI live captioning.
People mix these words up constantly, and most of the time it's harmless. It starts to matter when you're booking a service for an event, writing a budget line, or trying to make a multilingual conference work. Ask for "translation" at a live conference and you'll confuse the vendor; ask for an "interpreter" for your website copy and you'll get the same blank look. This piece draws the line clearly, then — because I run a tool in this space — explains honestly where AI live captioning does and doesn't replace a human interpreter.
Disclosure: I run Subanana, an AI speech-to-text tool with a live-caption mode, so I have a stake in the last section. The definitions below follow the standard industry distinction summarized by a professional language-services reference, a US federal language-access definition, and an academic clarification in a public-health journal, all fetched June 2026.

What is the difference between translation and interpretation?
The cleanest test is to ask one question: is the language written or spoken?
Translation is for written text. A translator takes a source document — a contract, a website, a manual, a subtitle file — and renders it into another language in writing. The defining feature is that the work isn't live. As the academic literature puts it, translation "involves longer time spans between the source production and the rendering into the target language," which gives the translator room to "consider alternative translations, research previously produced translations" and revise the final result. That time is a feature: it's why a good translation can be exact.
Interpretation is for the spoken word, in real time. An interpreter listens to someone speaking and renders it aloud into another language while the conversation is happening. US federal language-access guidance defines interpretation as exactly this — the oral rendering of speech from one language into another, as distinct from translation, which it reserves for written material. The defining feature here is immediacy: the interpreter, in the words of that same clarification, has to "process a piece of speech and render it — either simultaneously or consecutively — into the other language, without the opportunity to consider alternative renderings." There's no undo.
That single split — recorded text with time to perfect it, versus live speech with none — drives every other difference between the two fields:
| Translation | Interpretation | |
|---|---|---|
| Medium | Written text (documents, web, subtitles) | Spoken word (live speech) |
| Timing | After the fact — time to research and revise | Real time — rendered on the spot, no second take |
| Typical use case | Contracts, websites, books, manuals, subtitle files | Conferences, courtrooms, medical visits, diplomacy |
| Who does it | A translator, usually working into their native language, one direction | An interpreter, usually working both directions between a language pair |
| Tools at hand | Dictionaries, glossaries, reference material, editing time | Memory, listening skill, fast recall — no time to look things up |
| Output | A finished written file | Speech the audience hears live |
Two details in that table catch people out. First, direction: translators typically work one way, into their strongest language, because writing well in a second language is hard. Interpreters work bidirectionally — the same person handles both sides of a doctor-patient conversation, switching languages turn by turn. Second, reference material: a translator can stop and look up a term; an interpreter can't pause a live speaker to check a dictionary, which is why interpreting is as much about instant recall and nerve as it is about vocabulary.
Simultaneous vs consecutive interpreting — what's the difference?
Once you're in the spoken-language world, interpretation itself splits into two main modes. The difference is simply when the interpreter speaks relative to the original speaker.
Consecutive interpreting happens in turns. The speaker says a sentence or a few, then pauses; the interpreter — often working from notes — renders that chunk into the other language; then the speaker continues. You've seen this in a courtroom, a doctor's office, or a one-on-one business meeting. It roughly doubles the time a conversation takes, because every point is said twice, but it needs no special equipment and it's precise for back-and-forth dialogue.
Simultaneous interpreting happens at the same time as the speaker, with only a few seconds' lag. The interpreter listens and speaks almost concurrently, usually from a soundproof booth, with the audience listening through headsets. This is the mode used at the UN, at large international conferences, and anywhere a long talk has to reach a multilingual audience without doubling the runtime. It's cognitively brutal — simultaneous interpreters typically work in pairs and swap every 20-30 minutes — which is part of why it's expensive.
There's a third, smaller mode worth knowing: sight translation, where an interpreter reads a written document aloud in another language on the spot. It's the one place the two worlds overlap — written input, spoken output, in real time.
A quick way to remember which event needs which: a two-person conversation or a short statement to a small group → consecutive; a long talk or a conference to a large multilingual audience → simultaneous.
Where does AI live captioning fit?
Here's the part where my own product enters the picture, and I want to be precise about what it is and isn't.
For years there were only two ways to bridge a live language gap: hire a human interpreter (accurate, but expensive and bookable only one event at a time) or do without. AI changed the middle. AI live captioning transcribes a speaker in real time and can translate that text on the fly, displaying it on a screen or on each attendee's phone via a shared link. It's not an interpreter speaking into your ear — it's live, translated text you read while the talk happens. The newer systems aren't a raw single-pass feed either: the better ones run a real-time LLM-correction pass over the captions as they appear, which is what separates an accurate AI caption from a rough one.
That makes it a genuinely different category from both translation and interpretation:
| Translation | Interpretation | AI live captioning | |
|---|---|---|---|
| Input | Written text | Live speech | Live speech |
| Output | Written text | Spoken audio (live) | On-screen text (live), often translated |
| Timing | After the fact | Real time | Real time |
| Who/what does it | Human translator | Human interpreter | Speech recognition + machine translation, with a real-time LLM-correction pass on the better tools |
| Set-up | Send a document | Book a person (and booth, for simultaneous) | Route audio in, share a link |
| Best fit | Anything written | High-stakes spoken exchanges | The most accurate automatic option for live multilingual events |
Where AI live captioning earns its place is the long tail of events that were never going to hire a simultaneous-interpretation team: a community AGM, a university lecture with international students, a startup's all-hands, a church service, a mid-size conference on a normal budget. Booking simultaneous interpreters means a per-event professional fee plus equipment; AI captioning runs off a software subscription, sets up in minutes, and scales to as many events as you want. (For the deeper how-to on the captioning side specifically, I wrote a separate guide on what live captioning is and one on running multilingual live-caption events.)
And here's the honest boundary, because it's the whole point of being clear about these definitions: AI live captioning does not replace a certified human interpreter. A human simultaneous interpreter handles crosstalk, heavy accents, idiom, sarcasm, and high-stakes nuance with a judgment that automatic systems still can't guarantee in the moment — and for a courtroom, a medical consent conversation, a diplomatic negotiation, or any setting that demands a certified, regulated accuracy standard, a qualified human interpreter (or, for accessibility, a certified CART captioner) is the right call, not software. That boundary is about certification, not about AI captions being rough: among automatic options, an LLM-corrected live-caption tool is the accurate end of the range, not a cut-rate stand-in.
How Subanana's live captioning works
Subanana's real-time transcription is AI-automatic live captioning with translation, built around the audience-facing case. It transcribes the speaker and then runs a real-time LLM-correction pass over the captions before they reach the screen — which is what makes it far more accurate than a standard single-pass AI caption feed, and why it's the premium (Max-tier) option rather than a fast-but-rough one. The host opens a session, routes the event's audio in (a microphone or the system audio from a video call), and picks a source language plus one translation target. Attendees scan a QR code or open a shared link on their own phones and choose how to read it — original, translated, or both side by side. No app to install, no hardware to rent, no interpreter to book.
What it's actually good at:
- Accuracy, for an automatic tool. The real-time LLM-correction pass over the live caption stream is the core of it: it produces captions well above a standard single-pass AI feed, which is why this sits at the accurate, premium end of automatic live captioning rather than the budget end.
- Cantonese and mixed-language speech. Hong Kong events rarely stay in one clean language — a speaker slides between Cantonese and English mid-sentence. Subanana's live captioning treats Cantonese as a first-class source language and auto-detects that mid-utterance code-switching. For a long event that's cleanly segmented (an English first half, a Cantonese second half), the operator can switch the source language at the break for extra stability.
- Instant, audience-facing setup. The shared-link-to-every-phone model is the thing a booth-and-headset interpretation rig doesn't give you for a self-serve event.
- Multilingual on a normal plan. You get real-time translation without an enterprise contract or a per-event interpreter fee.
- A glossary the live session reads. You can pin brand names, people, and jargon ahead of time so they're less likely to be mangled in the moment.
And the honest scope, so you can rule it in or out fast:
- It's AI-automatic, not a human service. If you need certified, legal-grade accuracy, book a human interpreter or CART provider — that's not what this is.
- One translation target per live session. The host sets a single source plus a single target language; attendees choose display only, they can't each pick a different language live. (If you need several target languages at once, the workaround is one session per language on its own operator device. Multiple translation targets in a single job is a feature of our subtitle mode, not live captioning.)
- A live session exports as SRT. If you want a polished, paragraphed transcript or a Word/Excel file afterward, re-process the recording as a regular file upload — that's the transcription mode, which supports the broader format set.
The fastest way to find out whether AI live captioning clears the bar for your event is to run it on your own audio. The free tier lets you preview the result before you commit.
FAQ
What is the difference between translation and interpretation? Translation converts written text from one language to another and isn't done live — the translator has time to research and revise. Interpretation converts the spoken word in real time, as someone is talking, with no opportunity to revise. Different medium (text vs speech), different timing (after-the-fact vs live), and largely different skill sets.
Is interpretation the same as translation? No, though people use the words interchangeably. If the source is a document and the output is written, it's translation. If the source is live speech and the output is delivered in the moment, it's interpretation. The everyday overlap is harmless, but it matters when you're hiring a service or budgeting for an event.
What's the difference between simultaneous and consecutive interpreting? Consecutive interpreting happens in turns — the speaker pauses and the interpreter renders each chunk, common in courtrooms, medical visits, and small meetings. Simultaneous interpreting happens at the same time as the speaker with a few seconds' lag, usually from a booth with the audience on headsets, used at the UN and large conferences. Simultaneous is faster for big audiences but more demanding and more expensive.
Can AI replace a human interpreter? Not for high-stakes spoken exchanges. AI live captioning gives you real-time, translated text and is a strong fit for events that were never going to staff a human interpretation team — lectures, AGMs, mid-size conferences, webinars. But for a courtroom, a medical consent conversation, or any setting where a misrendered sentence carries real consequences, a certified human interpreter or CART provider is still the right call.
Is AI live captioning the same as interpretation? They're related but distinct. Both work on live speech in real time, but an interpreter produces spoken audio in another language, while AI live captioning produces on-screen text (often translated) that the audience reads. Captioning also serves deaf and hard-of-hearing attendees, which spoken interpretation doesn't.
Do I need translation or interpretation for my event? If your event is live and spoken, you need interpretation (a human interpreter) or AI live captioning, not translation. Translation is for written material — documents, slides, websites, subtitle files for a recording. A common combination is AI live captions during the event plus a translated transcript afterward.
Sources cited: Language Scientific — translation vs interpreting; LEP.gov — interpretation; PMC / public-health journal — language, interpretation, and translation clarification. Definitions fetched June 2026.